

Google Cloud published a reference architecture for multi-tenant agentic AI on 18 June 2026 (Awasthi and Bhardwaj, 2026). It is a clean, well-structured document covering the hub-and-spoke topology, the role of VPC Service Controls and Principal Access Boundary policies, where Model Armor sits, how Identity-Aware Proxy fronts the whole thing, and how the Agent Development Kit (ADK) builds orchestration that runs inside the Gemini Enterprise Agent Platform.
You should read it.
The source is Build a multi-tenant agentic AI system (Awasthi and Bhardwaj, 2026) and a reference Terraform module is published on the GoogleCloudPlatform GitHub org (Google Cloud Platform, 2026).
This post takes a look at that architecture the way you would walk it in a client engagement: name the decisions, pick the defaults, and call out the gaps you will hit between a reference architecture and a system that holds up in production. The reference is a sound starting point, and most of what follows is the work that happens after you have decided to use it.
The pattern at a glance
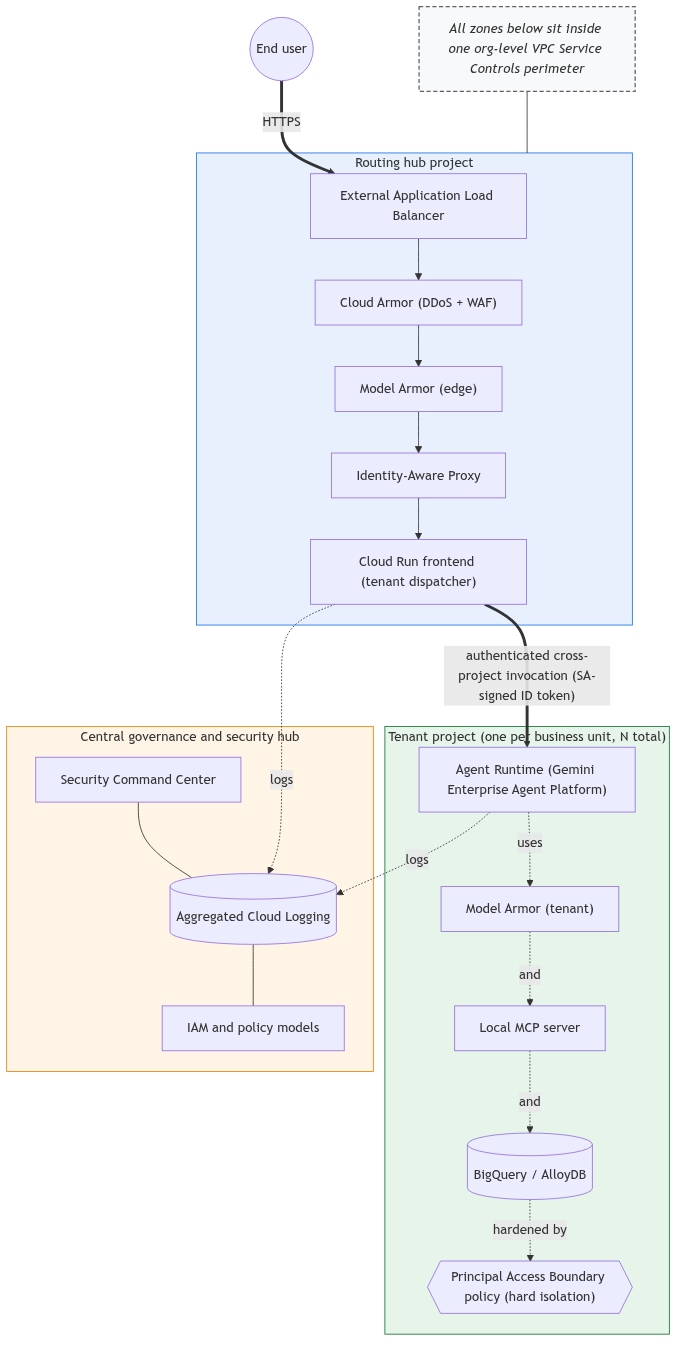
The architecture is hub-and-spoke. Three logical zones sit inside a single org-level VPC Service Controls perimeter:
- A routing hub at the edge that takes external traffic, terminates SSL, runs a WAF, checks identity, and dispatches the request to one of N tenant projects.
- A central governance and security hub, its own GCP project, holding Security Command Center, aggregated Cloud Logging from every hub and tenant, and the IAM models that operators work from.
- One tenant project per business unit, each holding its own agent runtime, its own datastore (BigQuery or AlloyDB for PostgreSQL), its own MCP server, its own Model Armor instance, and a per-tenant Gemini configuration.
The routing hub bundles an external Application Load Balancer (anycast, edge SSL termination), Google Cloud Armor (DDoS plus a WAF for SQLi, XSS and bot traffic), Model Armor injected into the load balancer via Service Extensions for prompt-injection scrubbing at the edge, Identity-Aware Proxy for zero-trust user and device verification, and a Cloud Run frontend portal acting as the routing engine. The Cloud Run frontend reads tenant identity out of the IAP context and dispatches the request to the right tenant project via a “dynamically maintained registry”.
The tenant project is the isolation primitive. Inside it, Principal Access Boundary (PAB) policies enforce that principals belonging to one tenant cannot reach resources in another, even by accident. The org-level VPC SC perimeter is the outer ring; PAB is the inner ring. Both matter, for different failure modes.
The governance hub does not serve traffic. It is where logs go, where operators look for trouble, and where shared services land if you choose to deploy any (a shared MCP server, for instance, lives in its own shared-services project that the governance hub watches but does not host).
That is the pattern. What follows is the set of decisions you will make implementing it.
Decision 1: Project per tenant, or namespace?
Google’s default is one GCP project per tenant (Awasthi and Bhardwaj, 2026). This is the right default for almost everyone, but it is worth knowing why.
Project is the strongest isolation primitive Google Cloud gives you. It is the boundary for IAM blast radius, for billing and quota, for audit logging, and for VPC Service Controls perimeter membership. A misconfigured IAM binding inside a project can ruin that project’s day. The same misconfiguration in a Kubernetes namespace can ruin the whole cluster.
Namespace-per-tenant on a shared GKE cluster is tempting when you are cost-sensitive and the number of tenants is small. You get one set of system pods, one Anthos/Cloud Service Mesh, one logging pipeline. You lose: hard quota per tenant (you have to enforce it with resource quotas you maintain yourself), independent billing without manual labels, perimeter isolation (one VPC SC perimeter has to cover all tenants), and clean IAM separation (everything is in the cluster’s IAM scope).
The crossover point is somewhere between five and twenty tenants depending on how strict your isolation requirements are. For most enterprise multi-tenant agent deployments, especially ones touching regulated data, take the project per tenant. You will not regret it.
The PAB policy itself is short. Once you have your tenant project, you set a policy at the project that enumerates which principals are allowed in, and the policy is enforced at the IAM evaluation step. A minimal PAB looks like this:
# pab-policy-tenant-fintech.yaml
displayName: "Hard isolation for fintech tenant"
rules:
- description: "Only fintech tenant principals and central operators"
effectiveResources:
- "//cloudresourcemanager.googleapis.com/projects/tenant-fintech-prod"
principalSet: |
principalSet://goog/group/[email protected],
principalSet://goog/group/[email protected]The thing to watch as you scale is VPC Service Controls perimeter lifecycle. Adding a tenant project means amending the perimeter. Always run perimeter changes in dry-run mode first, watch the dry-run violations for at least one full traffic cycle, and only then promote to enforced. Ingress and egress rules accumulate quickly. Group them by trust direction (inbound from corporate, outbound to first-party Google APIs, outbound to specific partner endpoints) and review the groupings quarterly. Perimeter sprawl is real and it bites when you are onboarding a new tenant in a hurry.
Decision 2: Edge Model Armor or per-tenant?
Google’s reference defaults to both. Model Armor sits at the edge, injected into the load balancer via Service Extensions, and runs again inside each tenant project (Awasthi and Bhardwaj, 2026). The cost-optimisation section of the doc proposes collapsing this to edge-only to cut latency and cost (Awasthi and Bhardwaj, 2026).
Defense in depth says keep both. Here is the practical reason.
The edge instance is your single source of truth for the prompt-injection signatures and policies that apply to everything you serve. New attack patterns, your house-style guardrails, jailbreak families: those live at the edge. The tenant instance enforces the tenant-specific contract: which topics this tenant is allowed to ask about, which response styles are forbidden, what PII shapes this tenant’s data even contains. A retail tenant and a banking tenant want very different second-layer policies.
If you collapse to edge-only you have one set of rules to maintain (good for ops) and you lose per-tenant policy expression (bad if you have more than two tenants with meaningful difference). If you collapse to tenant-only you push every signature update into N codepaths (slow to roll out, easy to drift) and you double your inspection latency.
Default: keep both. The tens-of-milliseconds latency hit is worth the defence in depth and the operational separation of concerns. If you have a tenant with a strict latency budget (sub-200ms total), measure both instances and consider exempting them from the edge layer with a documented risk acceptance.
Decision 3: Cloud Run or GKE for the frontend?
The doc says “Cloud Run or GKE” and waves at both (Awasthi and Bhardwaj, 2026). For the routing hub frontend specifically, Cloud Run wins.
The frontend portal is a thin component. It reads the IAP-validated headers, looks up the tenant in a registry, and proxies to the tenant. It has no persistent state and no specialised compute requirement. Cloud Run gives you zero infrastructure to manage, automatic SSL, request-based autoscaling, and direct integration with IAP, Cloud Armor and Service Extensions.
The cold-start objection comes up immediately. IAP does not queue requests behind a cold container. A cold Cloud Run instance plus an IAP handshake will show users a multi-second blank screen, and that is the moment they decide your platform is slow. The fix is to set min_instances on the Cloud Run service for any tenant frontend that has a user-facing SLO.
resource "google_cloud_run_v2_service" "tenant_frontend" {
name = "tenant-frontend"
location = "europe-west1"
project = var.routing_hub_project_id
template {
scaling {
min_instance_count = 2
max_instance_count = 50
}
containers {
image = var.frontend_image
resources {
cpu_idle = false # CPU always allocated; required for low latency
}
}
}
}cpu_idle = false is important. The default Cloud Run behaviour throttles CPU to near zero between requests on an idle instance. For a request-handling frontend that needs to respond fast even after a short idle period, you want CPU always allocated. It costs more. It is worth it.
Tenant-ID extraction is straightforward from the IAP context. The frontend reads x-goog-iap-jwt-assertion, verifies the signature against Google’s public keys, decodes the claims, and uses an email_verified claim combined with a group membership claim (or a direct mapping from email domain) to resolve which tenant project should receive the proxied request.
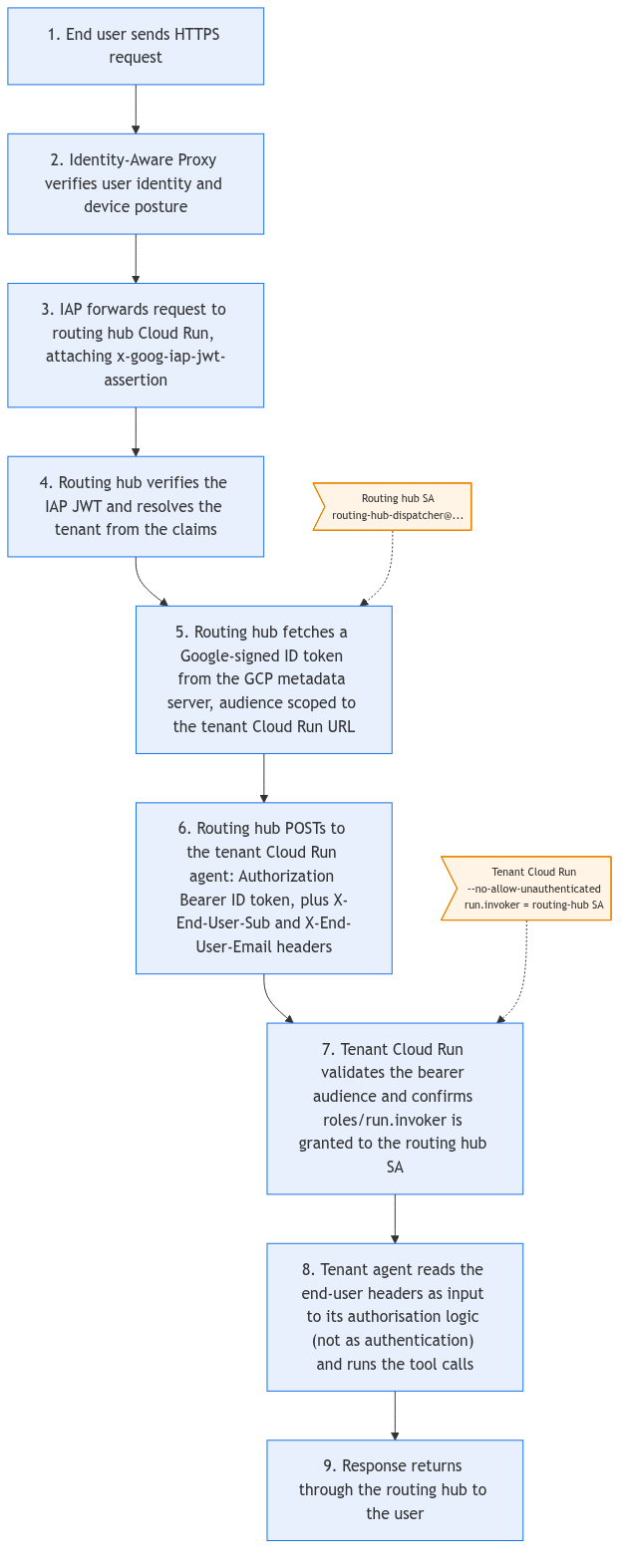
Then the cross-project hop, this where IAP runs out of usefulness: IAP only terminates user identity at the routing hub. The downstream tenant service has no IAP in front of it and no idea who the user was unless the routing frontend tells it explicitly. So the routing hub Cloud Run service runs as its own dedicated Google service account (call it routing-hub-dispatcher@routing-hub-project.iam.gserviceaccount.com), and that service account invokes the tenant Cloud Run service over HTTPS with a Google-signed ID token in the Authorization header. The tenant Cloud Run service is deployed with --no-allow-unauthenticated (strict Require authentication in the IAM console) and grants roles/run.invoker only to the routing hub’s service account. The end-user identity (subject, email, verified claims) gets passed in signed request headers attached to the proxied call, and the tenant agent treats those headers as input to its authorisation logic, not as authentication.
# Tenant Cloud Run agent: require authentication, only the routing
# hub's service account can invoke
resource "google_cloud_run_v2_service" "tenant_agent" {
name = "tenant-agent"
location = "europe-west1"
project = var.tenant_project_id
ingress = "INGRESS_TRAFFIC_INTERNAL_LOAD_BALANCER"
template {
service_account = google_service_account.tenant_agent_sa.email
# ... container spec
}
}
resource "google_cloud_run_v2_service_iam_binding" "tenant_agent_invoker" {
project = google_cloud_run_v2_service.tenant_agent.project
location = google_cloud_run_v2_service.tenant_agent.location
name = google_cloud_run_v2_service.tenant_agent.name
role = "roles/run.invoker"
members = [
"serviceAccount:routing-hub-dispatcher@${var.routing_hub_project_id}.iam.gserviceaccount.com",
]
}That is the policy on the receiving end. The calling side lives in the routing hub: fetch a Google-signed ID token whose audience is the tenant service’s URL, attach it as the bearer credential, and pass the end-user identity across in signed headers alongside it.
# Routing hub: fetch a Google-signed ID token audience-scoped to the
# tenant Cloud Run URL, attach it to the proxied request
from google.auth import default
from google.auth.transport.requests import Request
from google.oauth2 import id_token
def proxy_to_tenant(tenant_url, iap_claims, body):
auth_req = Request()
token = id_token.fetch_id_token(auth_req, audience=tenant_url)
headers = {
"Authorization": f"Bearer {token}",
"X-End-User-Sub": iap_claims["sub"],
"X-End-User-Email": iap_claims["email"],
"X-Tenant-Id": resolve_tenant(iap_claims),
}
return requests.post(tenant_url, headers=headers, json=body)This pattern keeps the chain auditable (every cross-project invocation has a signed ID token tied to a known service account), prevents lateral movement (no one outside the routing hub’s SA can call the tenant service), and keeps end-user identity flowing through to the agent for tool-call authorisation. A common mistake is to make the tenant Cloud Run service allUsers and rely on “internal” network controls; do not. The tenant service should be reachable only through an authenticated cross-project invocation from the routing hub, no exceptions.
GKE is the right choice when the frontend is not thin. If you are doing inline transformation, request hydration, or any heavy work between the IAP layer and the tenant dispatch, the operational uplift of GKE buys you more control. For the standard case, stay on Cloud Run.
Decision 4: MCP servers, local or shared?
The Model Context Protocol is an open-source standard originally introduced by Anthropic in late 2024 (Anthropic, 2024), now being adopted into Google Cloud architectures rather than a proprietary Google primitive. Treat it as industry plumbing: open implementations from outside the Google ecosystem will run inside the tenant project unchanged.
The reference architecture gives you two MCP deployment patterns, and the choice is important:
- Local MCP server per tenant - the MCP server lives inside the tenant project. Tenant data and tenant tools never leave the project boundary. PAB and VPC SC do the isolation automatically. This is the right default for any tenant whose tools touch sensitive or regulated data. It is also the right default if your tenants do not share tools at all.
- Shared MCP server - the MCP server lives in a shared-services project, reached from tenant agents via Private Service Connect or VPC peering. This is the pattern for corporate-wide tools that every tenant needs (HR systems, expense tools, the corporate knowledge base, that sort of thing). The win is that you maintain one MCP server, one set of upstream API integrations, and one ACL model on the backend.
The cost is identity propagation, and the GCP doc hand-waves it. The doc says you must “securely propagate the end-user identity from the agent in the tenant project to the shared MCP server” so the MCP server can enforce fine-grained access on the backend (Awasthi and Bhardwaj, 2026). It does not say how.
There are essentially four options, and only two of them are real.
- Plain bearer tokens: The tenant agent passes through the user’s access token. Do not do this. Bearer tokens leak, and any compromise of the MCP server compromises every tenant’s tokens.
- Service-account impersonation chains: The tenant agent’s service account impersonates a per-user service account that has the right ACLs on the shared backend. Works, but the impersonation chain creates an audit-trail mess and the per-user service-account sprawl becomes its own management problem.
- OIDC token exchange via Google’s STS: The tenant agent’s workload identity gets a short-lived OIDC ID token (audience-scoped to the shared MCP), STS exchanges it for an access token, and the shared MCP server validates the audience and the embedded end-user claims. Clean, auditable, scales.
- Signed JWTs with workload-issued certs Like option 3 but you run your own signing infrastructure. Use only if you have a sovereignty requirement that rules out STS.
OIDC token exchange via STS is the right default. The flow looks like this end to end:
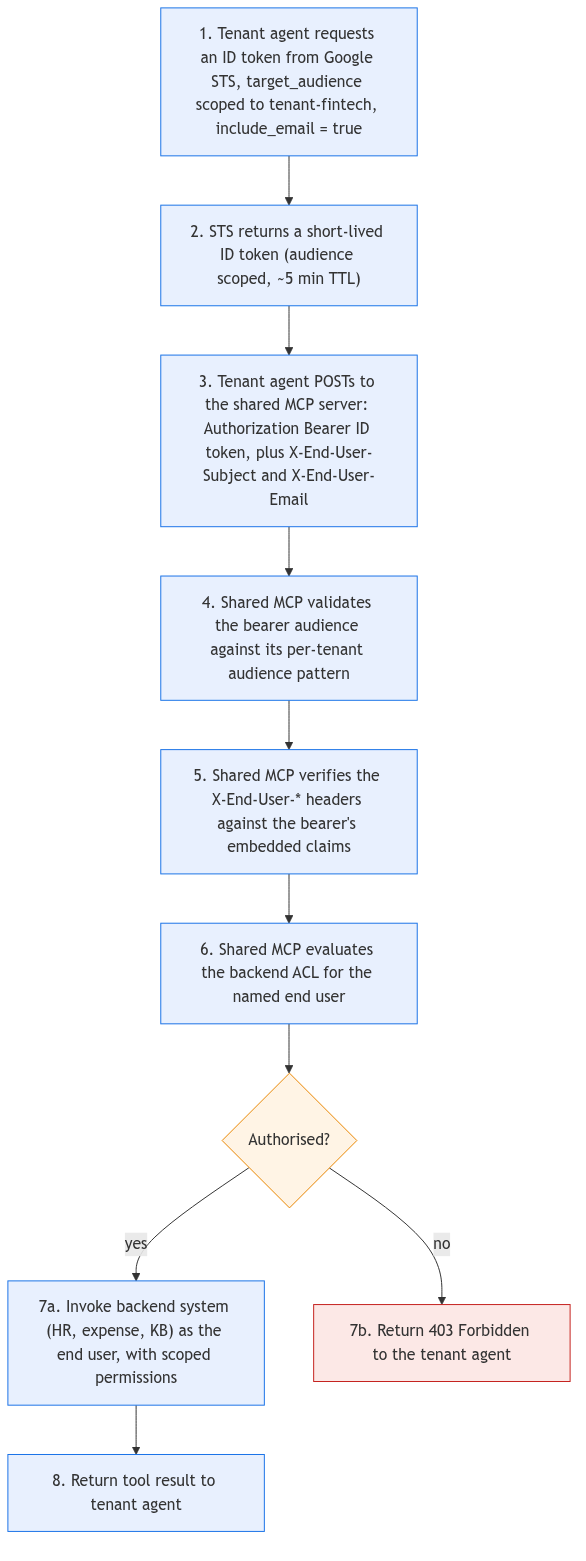
The shape of the call from the tenant agent looks like this:
# tenant agent code (Python, simplified)
from google.auth import impersonated_credentials
from google.auth.transport.requests import Request
# 1. Get the agent's workload identity credentials
source_creds = google.auth.default()[0]
# 2. Request an OIDC ID token, audience-scoped to the shared MCP
id_creds = impersonated_credentials.IDTokenCredentials(
source_creds,
target_audience="//mcp.shared.example.com/audience/tenant-fintech",
include_email=True,
)
# 3. Stamp the end-user claim into the request before forwarding
def call_shared_mcp(user_identity, tool_name, args):
id_creds.refresh(Request())
headers = {
"Authorization": f"Bearer {id_creds.token}",
"X-End-User-Subject": user_identity.subject,
"X-End-User-Email": user_identity.email,
}
# Shared MCP verifies the bearer audience AND the end-user headers
return requests.post(
f"https://mcp.shared.example.com/tools/{tool_name}",
headers=headers,
json=args,
)The shared MCP server validates the bearer token’s audience against its expected pattern (one audience per tenant means you can revoke a tenant’s access without rotating the whole signing key), verifies the end-user headers against the bearer’s embedded claims, and only then evaluates the backend ACL.
Two pitfalls to flag.
- First: do not let the tenant agent set the end-user headers without binding them to the bearer audience. The headers must be cryptographically tied to the token, otherwise the tenant agent can impersonate any end user.
- Second: keep token lifetimes short. Five minutes is generous. The whole pattern relies on the tokens being uninteresting to steal.
Decision 5: Tenant data plane and DR
The reference architecture covers HA for the load balancer layer. It says next to nothing about DR for the tenant data plane, which is where your actual customer data lives.
The two datastore options the doc presents (BigQuery and AlloyDB for PostgreSQL) have very different operational profiles for DR.
- BigQuery is regional by default. The native managed capability for cross-region availability is BigQuery Cross-Region Dataset Replication: you configure a replica of the dataset in a second region, and BigQuery handles the asynchronous replication for you. This is what you should reach for first. Scheduled query replication and the managed dataset copy primitive both still exist, but they are fallbacks for the edge cases (cross-organisation copies, partial-table replicas, schema transformations) rather than the default DR mechanism. What Cross-Region Dataset Replication does not give you is automatic failover. The replica is queryable, but your agent’s RAG retrieval is still configured against the primary dataset’s project and region; flipping retrieval over to the replica during a regional outage is a manual configuration change. Plan the runbook before you need it, and test the flip on a non-prod tenant at least quarterly.
- AlloyDB for PostgreSQL offers cross-region read pools and managed failover. The failover is faster than the BigQuery equivalent, but you pay for the standby capacity continuously. Suitable if you have low RTO/RPO targets and your tenant’s data fits the relational shape.
A useful heuristic: BigQuery for tenants whose RAG corpus is large, mostly read, and tolerant of an hour or two of stale data in a regional failover. AlloyDB for tenants whose agent reads and writes transactional state, where stale data causes correctness problems.
The encryption story is the other gap. The GCP doc claims “data sovereignty” several times without naming a key management story. If you actually have a sovereignty requirement, use Customer-Managed Encryption Keys (CMEK) via Cloud KMS at minimum, External Key Manager (EKM) if your jurisdiction requires keys never to be in Google’s infrastructure, or Confidential Computing if your threat model includes the cloud operator. Most enterprise multi-tenant agent deployments are well-served by CMEK with per-tenant key rings and a clear key-rotation policy. Confidential Computing is overkill for most, the right call for some.
Decision 6: Model endpoints, dedicated or shared?
The Gemini model can be served from per-tenant dedicated endpoints, or from shared endpoints in the governance hub fronted by an API gateway with rate limiting.
Dedicated per-tenant: highest cost, lowest blast radius, lets you set Provisioned Throughput per tenant. Provisioned Throughput is the mechanism that prevents the 429s the doc warns about, and Memorystore for Redis is the recommended counter store for per-tenant rate limiting at your gateway layer (Awasthi and Bhardwaj, 2026).
Shared endpoints in the governance hub: lower cost, requires careful rate limiting to prevent one tenant starving another, and requires labelling discipline if you want clean per-tenant cost attribution.
Default: dedicated if the tenant has an SLA or a sovereignty constraint that ties them to a specific deployment. Shared otherwise, with a per-tenant rate-limit budget enforced at the gateway. The cost difference is meaningful at scale and a noisy-neighbour incident on shared endpoints is recoverable, where a missed SLA on a dedicated endpoint with no headroom is not.
The observability the doc misses
Cloud Logging aggregated to the governance hub is fine for platform logs. It tells you when a Cloud Run instance crashed, when an IAP check failed, when a VPC SC violation was raised. It does not tell you what the agent did.
For agent observability you need three things the reference does not call out: tool-call tracing, semantic eval pipelines, and tenant-attributed cost tracking.
Tool-call tracing with OpenTelemetry. ADK orchestration is regular Python; wrap it. Every tool call gets a span. Every tool-call argument and (where not sensitive) the return value goes in span attributes. Every agent turn becomes a trace. The trace ID lives in your logs alongside the IAP user ID and the tenant ID. When something looks wrong, you can pull the full reasoning trace for the affected request.
# OTEL wrapper around an ADK tool registration
from opentelemetry import trace
tracer = trace.get_tracer("sakura.tenant.agent")
def traced_tool(tool_fn):
def wrapped(*args, **kwargs):
with tracer.start_as_current_span(f"tool.{tool_fn.__name__}") as span:
span.set_attribute("tenant.id", current_tenant_id())
span.set_attribute("user.subject", current_user_subject())
span.set_attribute("tool.args", json.dumps(args))
try:
result = tool_fn(*args, **kwargs)
span.set_attribute("tool.outcome", "ok")
return result
except Exception as e:
span.set_attribute("tool.outcome", "error")
span.record_exception(e)
raise
return wrappedSemantic eval pipelines. The agent’s correctness has nothing to do with whether the Cloud Run instance is healthy. Stand up a tenant-owned eval set: a fixed list of prompts with expected behavioural properties (not exact-match responses, but properties like “must call the fraud-check tool”, “must not return PII”, “must hand off to human review when confidence below 0.7”). Run the eval set on every agent version change. Gate the rollout on the result.
Tenant-attributed cost. The GCP doc names three cost-allocation models: even split, proportional, and fixed/tiered (Awasthi and Bhardwaj, 2026). The right default is proportional with a fixed-tier floor for shared services. Tenants pay for what they consume (model invocations, data scanned, agent-runtime CPU-seconds) plus a baseline contribution to the shared services they benefit from (the governance hub, the routing hub, the shared MCP server if used). Label everything at deployment time via Resource Manager labels; the Cloud Billing export to BigQuery does the rest. To be clear about scope: the billing export is for after-the-fact attribution and reconciliation only, not for real-time enforcement of anything.
One thing the doc does not mention at all: per-tenant spend caps. Without them, a runaway agent or a malicious prompt can rack up tens of thousands of dollars in model spend pretty quickly.
The first instinct is to wire a Cloud Function against the BigQuery billing export and call that your circuit breaker. Do not. The Cloud Billing export to BigQuery is a reconciliation feed, not a real-time signal: settled rows can lag the actual API call by hours, sometimes most of a day. By the time the export tells you a tenant is over budget, the damage is paid for.
The real-time cap has to run where the spend actually originates. The routing gateway already sees every model invocation as it leaves the tenant; it already has a per-tenant Memorystore instance for rate limiting. Track token consumption and an estimated cost in the same Redis keys. On each model call, the gateway increments the tenant’s rolling spend counter by the priced token count returned in the model response. When the counter crosses the soft cap, flip a feature flag that pauses non-essential tool calls. When it crosses the hard cap, return a 429 with a maintenance message and suspend the tenant’s agent service account. The BigQuery billing export remains useful: it is the source of truth for end-of-month reconciliation and for catching drift between the gateway’s priced-token estimate and Google’s actual billed amount. It is not the source of truth for live enforcement.
# Per-tenant real-time spend cap, tracked at the routing gateway
import redis
r = redis.Redis(host=MEMORYSTORE_HOST, port=6379, db=0)
# Pricing constants (refresh from Cloud Billing Catalog API on a schedule)
PRICE_PER_1K_INPUT = 0.00125 # USD per 1K input tokens
PRICE_PER_1K_OUTPUT = 0.00375 # USD per 1K output tokens
def record_model_call(tenant_id, usage):
cost_usd = (
usage.prompt_tokens / 1000.0 * PRICE_PER_1K_INPUT +
usage.completion_tokens / 1000.0 * PRICE_PER_1K_OUTPUT
)
key = f"spend:{tenant_id}:{utc_hour_bucket()}"
new_total = r.incrbyfloat(key, cost_usd)
r.expire(key, 86400) # 24h ring buffer
return new_total
def check_spend_cap(tenant_id):
rolling_24h = sum(
float(r.get(f"spend:{tenant_id}:{h}") or 0)
for h in last_24_hour_buckets()
)
budget = TENANT_BUDGETS[tenant_id]
if rolling_24h >= budget["hard_cap"]:
return "STOP" # 429 + suspend service account
if rolling_24h >= budget["soft_cap"]:
return "DEGRADE" # pause non-essential tool calls
return "OK"Two operational notes on this. First, prices change; refresh PRICE_PER_1K_INPUT and friends from the Cloud Billing Catalog API on a daily schedule rather than hardcoding them. Second, your gateway estimate will not exactly match Google’s billed amount because of partial-token rounding, retries, and edge-case discounts. Tolerate drift of a few percent and reconcile against the billing export weekly.
Runaway behaviour: the bit you will actually wake up to
This section is for those on-call and doing a rotation as an SRE. What keeps you up at night? What will fire and alert and get you out of bed?
The failure modes below are the ones that page someone at 3am: silent prompt-injection via tool output, runaway code execution in an under-sandboxed tool, a tenant whose agent has entered a bad loop and is burning budget faster than the dashboards can catch. The platform team has to design these out up front, because by the time the alert fires, the operator’s only useful move is to pull the kill switch.
Google’s posture on runaway behaviour is: session token caps, 429 backoff with retry-with-jitter, and Model Armor at edge plus tenant (Awasthi and Bhardwaj, 2026). That covers the “prompt asks the model to write an infinite loop” case. It does not cover the cases that will actually wake you up.
Tool output exfiltration. An agent calls a tool. The tool returns. The tool’s return value is then passed back to the model as context. If a malicious or compromised tool returns content shaped like a prompt-injection, the model may act on it. Defence: every tool output must be schema-validated and run through the same prompt-injection filter as user input before it ever sees the agent loop. Treat tool outputs as untrusted input from the moment they leave the tool.
Code-interpreter style tools. If any of your tools execute user-influenced code (a SQL query against an analytics warehouse counts; a Python interpreter tool obviously counts), the execution sandbox is the security boundary. The GCP reference does not give you a sandbox pattern. Build one: a separate project, with no network egress except to the explicit data sources the tool needs, no IAM bindings to anything sensitive, and a hard time limit on every invocation. If you are using GKE, this is a separate namespace with NetworkPolicy denying everything. If you are on Cloud Run, deploy the sandbox as a separate Cloud Run service with VPC egress disabled.
Per-tenant circuit breakers. These ride on the same per-tenant Memorystore instance that backs rate limiting and the real-time spend cap described above. The breaker reads and updates two rolling counters inline on every request: rolling spend (priced at the gateway from token usage, per Decision 6 and the spend-cap pattern in the previous section) and rolling error rate. Trip the soft state on the soft cap or on an elevated error rate, pausing non-essential tool calls. Trip the hard state on the hard cap or a sustained error spike, returning 429 and suspending the tenant’s agent service account until an operator clears the breaker. The BigQuery billing export plays no role here; it is reconciliation, not enforcement.
The kill switch. The reference does not give you one. Build it at the load balancer: a single header (X-Maintenance-Mode: true) that, when set, returns a static maintenance page to all tenant requests. Wire it to a Cloud Function that any on-call engineer can invoke from a runbook. You will use it once, and when you use it you will be very glad it exists.
Versioning and rollout
The reference is silent on agent versioning. This is a significant omission, because every agent version change is a behaviour change, and without canary discipline every change is a full-tenant deploy.
The pattern: ADK orchestration code is versioned in source control like any other Python. Each version is deployed to Agent Runtime with an explicit version tag. The frontend or the per-tenant agent service routes a configurable percentage of traffic to the new version, based on a Memorystore-stored feature flag.
# Per-tenant version split via Memorystore feature flag
async def dispatch_to_agent_version(tenant_id, user_id, request):
flag = await memorystore.get(f"agent_version:{tenant_id}")
# flag is e.g. {"stable": "v1.4.2", "canary": "v1.5.0-rc.1", "canary_pct": 5}
if hash_to_bucket(user_id, 100) < flag["canary_pct"]:
return await call_agent_version(flag["canary"], request)
return await call_agent_version(flag["stable"], request)Tie the canary percentage to an eval gate. The new version starts at 0% and only advances if the tenant-owned eval set passes against the canary’s recorded responses. Run the eval continuously while the canary is live. If the eval starts failing, roll back automatically. Promote to stable only when the eval has held for a defined window (a few days for low-risk tenants, a couple of weeks for high-risk ones).
This pattern adds operational complexity but it is the difference between “we shipped a new agent and it broke tenant X” and “we ran a canary, the eval caught the regression, and we rolled back automatically”. For multi-tenant deployments where a single bad agent version damages trust across all tenants, the operational complexity is justified.
What we would ship, what we would skip
The defaults we would take from the reference unchanged: project per tenant; PAB plus VPC SC; both Model Armor instances; IAP at the edge; Cloud Run for the routing frontend; per-tenant Memorystore for rate limiting; Cloud Logging aggregation to the governance hub; the dynamic tenant registry once you are past about ten tenants.
What we would add: tenant data-plane DR (BigQuery replicas or AlloyDB cross-region read pools, with a tested runbook); CMEK with Cloud KMS per-tenant key rings; OIDC token exchange via STS for any shared MCP server; OpenTelemetry on the ADK orchestration with per-tenant trace attribution; per-tenant spend caps wired to a graceful-degradation feature flag and a hard stop; tool-output schema validation and re-running outputs through Model Armor before the agent sees them; an isolated execution sandbox for any tool that runs user-influenced code; a canary plus eval gate for agent version rollouts; a kill switch at the load balancer.
What we would skip on small deployments: the dynamic frontend routing registry (a static tenant map in source control is simpler and entirely adequate until you have more than a handful of tenants); shared model endpoints (the cost saving rarely justifies the noisy-neighbour risk until you are at significant scale); Confidential Computing (CMEK with KMS covers most sovereignty stories; Confidential Computing is for the small set of cases where the cloud operator is in the threat model).
The reference architecture is a good map. The work between “we picked that map” and “this thing is in production” is what determines whether the platform is something you can sleep through, or something that pages you at three in the morning. Most of that work is not in the reference, because it cannot be: every tenant mix, every regulatory context, every operational maturity is different. The reference gives you a sound topology. The decisions above are how you make that topology survive contact with the real world.
If you want to talk through how this maps to your environment, Sakura Sky’s Cloud, Data & AI, and Security practices build and run this kind of architecture for clients as production engagements. Enclave is our solution for the governed multi-project cloud organisation that hosts a deployment like the one above; Sentinel is the runtime governance layer you would put around the agent runtime to handle the observability, tool-call defence, and version gating discussed in the second half of this post.
Disclosure: Enclave and Sentinel are Sakura Sky offerings, and the Cloud, Data & AI, and Security practices referenced are Sakura Sky practice lines. Specific Google Cloud product behaviour and configuration in this article reflects the cited Google Cloud documentation; operational recommendations, defaults, and gap analysis are the author’s own and have not been reviewed by Google.
References
Anthropic, 2024. Introducing the Model Context Protocol. Anthropic. Available at: https://www.anthropic.com/news/model-context-protocol [Accessed 24 June 2026].
Awasthi, S. and Bhardwaj, U., 2026. Build a multi-tenant agentic AI system. Google Cloud Architecture Center. Last reviewed 18 June 2026. Available at: https://docs.cloud.google.com/architecture/multi-tenant-agentic-ai-system [Accessed 24 June 2026].
Google, n.d. Agent Development Kit (ADK). Available at: https://adk.dev [Accessed 24 June 2026].
Google Cloud Platform, 2026. terraform-google-multi-tenant-agentic-ai: Reference Terraform module for the multi-tenant agentic AI architecture. GitHub. Available at: https://github.com/GoogleCloudPlatform/architecture-center-samples/tree/main/terraform-google-multi-tenant-agentic-ai [Accessed 24 June 2026].
Google Research, 2024. Google’s Approach for Secure AI Agents. Google. Available at: https://storage.googleapis.com/gweb-research2023-media/pubtools/1018686.pdf [Accessed 24 June 2026].