


The Trustworthy AI Blueprint
This series began with a simple thesis:
AI agents cannot be trusted simply because they perform well.
They must be engineered to be trustworthy.
This series introduced a set of primitives - foundational capabilities that together form the safety substrate beneath any autonomous system.
Below is the complete list of the 16 Trustworthy AI primitives:
- Part 0 - Introduction
- Part 1 - End-to-End Encryption
- Part 2 - Prompt Injection Protection
- Part 3 - Agent Identity and Attestation
- Part 4 - Policy-as-Code Enforcement
- Part 5 - Verifiable Audit Logs
- Part 6 - Kill Switches and Circuit Breakers
- Part 7 - Adversarial Robustness
- Part 8 - Deterministic Replay
- Part 9 - Formal Verification of Constraints
- Part 10 - Secure Multi-Agent Protocols
- Part 11 - Agent Lifecycle Management
- Part 12 - Resource Governance
- Part 13 - Distributed Agent Orchestration
- Part 14 - Secure Memory Governance
- Part 15 - Agent-Native Observability
- Part 16 - Human-in-the-Loop Governance
- Part 17 - Conclusion (Operational Risk Modeling)
Individually, each primitive solves one class of risk. Together, they create a coherent operating model for trustworthy AI.
The Trustworthy AI Blueprint (Conclusion)
Trustworthy AI is a system of systems, it is not a monolith - it is a coordinated system of subsystems.
The four architectural layers work in sequence, each enabling the next:
- Identity & Cryptographic Foundations: Parts 1–3
- Runtime Enforcement Plane: Parts 4–9
- State & Memory Governance: Parts 10–14
- Semantic Observability & Human Oversight: Parts 15–16
These layers are best understood visually:

These layers form the conceptual backbone of the entire series.
Layer 1: Identity & Cryptographic Foundations (Parts 1–3)
Trusted automation begins with trusted identity. End-to-end encryption (Part 1), prompt injection hardening (Part 2), and SPIFFE-style identity & attestation (Part 3) ensure:
- every agent has a verifiable identity
- every message is authenticated
- every interaction is encrypted
- every tool call or memory access is accountable
This layer establishes trust at the boundary - preventing unverified components from entering the system and compromising the safety core.
Layer 2: Runtime Enforcement Plane (Parts 4–9)
Once identity is established, the system must enforce rules in motion:
- Policy-as-Code (Part 4) turns policies into executable rules.
- Kill switches & circuit breakers (Part 6) provide emergency cutoff paths.
- Adversarial robustness (Part 7) protects against poisoning and manipulation.
- Deterministic replay (Part 8) makes execution reproducible and debuggable.
- Formal verification (Part 9) encodes invariants such as “never exceed credit limits.”
This layer defines a mathematically bounded execution envelope, ensuring agents never operate unconstrained.
Layer 3: State & Memory Governance (Parts 10–14)
Agents rely on persistent state, shared memory, distributed workflows, and multitenant knowledge stores. Without governance, memory becomes the system’s largest blast radius.
This layer introduces:
- Secure Multi-Agent Protocols (Part 10)
- Agent Lifecycle Management (Part 11)
- Resource Governance (Part 12)
- Distributed Orchestration (Part 13)
- Secure Memory Governance (Part 14)
The outcome is a governed substrate where state is:
- structured
- validated
- versioned
- isolated
- encrypted
- auditable
Memory is no longer a risk - it’s a controlled resource.
Layer 4: Semantic Observability & Human Oversight (Parts 15–16)
Traditional telemetry cannot explain LLM behavior.
Agents require observability at the semantic level, not just the infrastructural one.
Agent-Native Observability (Part 15) introduces:
- reasoning traces
- tool-call graphs
- workflow lineage
- memory influence maps
- divergence analysis
- provenance DAGs
This transforms opaque behavior into structured, analyzable data.
Human-in-the-Loop Governance (Part 16) adds the final safety control:
- approval gates
- break-glass override
- reviewer workflows
- accountable decision logs
- exception workflows
- human-operated rollback
Humans become the final arbiter of high-risk agent decisions, closing the governance loop.
Diagram: End-to-End Trust Pipeline
This diagram represents the closed-loop safety cycle where identity, enforcement, memory, and observability flow continuously into human governance.
The final output (human judgments) feeds back into enforcement, making the system safer over time.

This is the heartbeat of trustworthy autonomy.
Operational Risk Modeling (ORM)
Operational Risk Modeling (ORM) is not itself a primitive - it is the analytical framework built on top of all 16 primitives - a methodology that emerges once the primitives exist.
ORM uses Formal Verification (Part 9) and Agent-Native Observability (Part 15) to quantify the blast radius and likelihood of harmful behavior.
ORM synthesizes three core components as per below.
1. Formal Verification Defines Limits (Part 9)
Formal invariants provide the “physics” of the system - firm boundaries such as:
- exposure_after ≤ credit_limit
- pii_encrypted = true
- tool calls must match capability claims
These invariants create the conditions under which risk can be mathematically scored.
2. Observability Supplies Signals (Part 15)
ORM consumes signals such as:
- divergence spikes
- anomalous memory-influence
- unusual tool-call chains
- provenance inconsistencies
- deviation from workflow lineage norms
These signals quantify the system’s behavioral risk posture.
3. HITL Governance Applies Human Judgment (Part 16)
While ORM produces risk levels, it is HITL that determines what to do about them:
- block
- warn
- escalate
- approve
- modify
- override
This creates a continuous safety loop where:
- technical limits define what is allowed,
- observability signals indicate what is happening,
- risk scoring quantifies likelihood and severity,
- humans make final governance decisions.
Diagram: ORM as the Capstone Layer
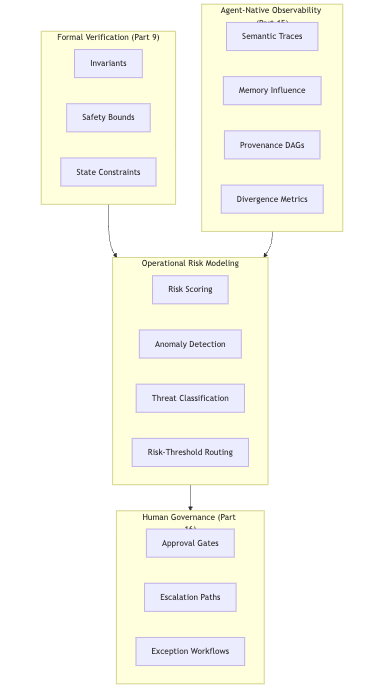
ORM is the analytical apex that transforms raw safety primitives into organizational decision-making.
Trustworthy AI: A Unified Operating Model
When assembled, the 16 primitives create an intelligent system with:
- cryptographically provable identity
- runtime safety enforcements
- structured, governed memory
- semantic behavioral observability
- human oversight for high-risk actions
- replayable, auditable, verifiable traces
- formal mathematical constraints
- continuous RLHF-based refinement loops
- risk scoring and governance routing
This is no longer “AI safety” or “best practices.” It is a complete, integrated framework for building trustworthy AI.
Final Words
Autonomy is inevitable, trustworthiness is not.
But we now have the blueprint to build it:
- strong identity
- enforceable rules
- governable memory
- explainable behavior
- human-centered oversight
- and a risk model tying everything together
These primitives form the foundation of AI systems that are not just powerful, but safe - not just capable, but accountable.
This concludes the series.


