


The Missing Primitives for Trustworthy AI Agents
This installment continues our exploration of the primitives required to build safe, predictable, production-grade AI agent ecosystems:
- Part 0 - Introduction
- Part 1 - End-to-End Encryption
- Part 2 - Prompt Injection Protection
- Part 3 - Agent Identity and Attestation
- Part 4 - Policy-as-Code Enforcement
- Part 5 - Verifiable Audit Logs
- Part 6 - Kill Switches and Circuit Breakers
- Part 7 - Adversarial Robustness
- Part 8 - Deterministic Replay
- Part 9 - Formal Verification of Constraints
- Part 10 - Secure Multi-Agent Protocols
- Part 11 - Agent Lifecycle Management
- Part 12 - Resource Governance
- Part 13 - Distributed Agent Orchestration
- Part 14 - Secure Memory Governance
- Part 15 - Agent-Native Observability
- Part 16 - Human-in-the-Loop Governance
- Part 17 - Conclusion (Operational Risk Modeling)
Distributed Agent Orchestration (Part 13)
If Part 12 showed how to prevent agents from overwhelming the system, Part 13 defines the system they must operate within.
Today, teams are running multi-agent systems with almost no orchestration layer. Agents communicate directly, freely spawn tasks, and rely on ad-hoc scheduling or whatever the underlying queue happens to do by default. This is similar to deploying microservices without Kubernetes, without a service mesh, without routing policies, and without any notion of coordinated workflows.
Agents behave like distributed actors, but we often run them like scripts.
Distributed agent orchestration is the missing primitive that brings order to this chaos. It is the control plane that manages routing, scheduling, failover, scalability, dependency coordination, and cost-aware decision-making across the entire agent ecosystem.
Without orchestration, multi-agent systems eventually devolve into:
- unpredictable inter-agent loops
- unbounded concurrency spikes
- inconsistent tool schemas
- nondeterministic workflow paths
- partial failures that cascade
- cost explosions caused by inefficient routing
- silent breakages between agent versions
Orchestration is the primitive that ties safety, governance, scheduling, economics, and interoperability together.
High level orchestration view
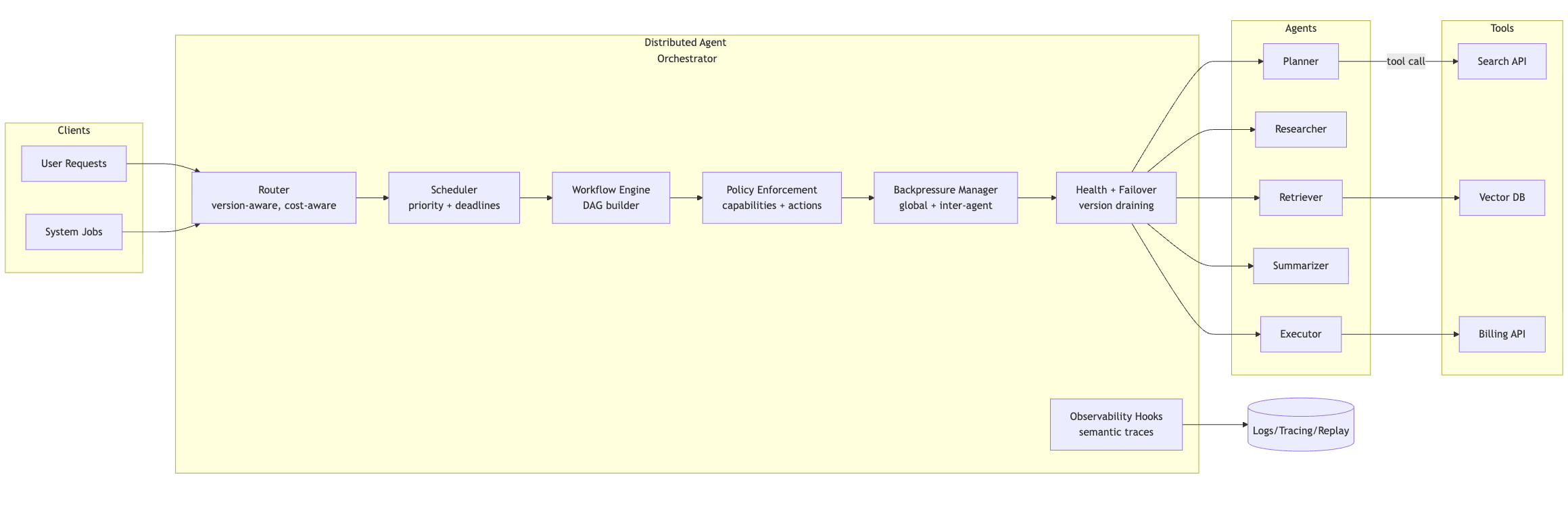
Why Agents Need a Control Plane
Traditional microservices rely on service discovery, routing, circuit breaking, load shedding, resource scheduling, version-aware rollout, health checks, and traffic shaping. They assume relatively stable behavior and clear request boundaries.
Agents break these assumptions. They are stateful, probabilistic, and task-generating. A single call can expand into a chain of reasoning steps, tool calls, and new tasks. Orchestration has to coordinate:
- model invocations and retries
- long running plans and workflows
- chains of tool calls
- dynamic multi-agent routes
- schema and version negotiation
- resource budgets and cost
- safety and policy checks
It must also manage trade-offs: latency versus accuracy, cost versus depth of reasoning, and safety versus autonomy. If this logic is pushed into each agent, the system becomes impossible to reason about. A central control plane keeps these trade-offs explicit and observable.
Orchestration in this context is not just infrastructure. It is governance, economics, safety, and routing logic fused into one layer.
Primitive 1: Routing (Intelligent, Cost Aware, Version Aware)
Agent systems often have several choices for where to send a task. There might be multiple versions of a planner agent, different LLM backends, or multiple tools that can satisfy the same capability. The routing layer decides:
- which agent version should handle the request
- which model tier to call (fast, cheap, large, domain specific)
- which region or cluster should execute the task
- whether to route through a fallback or cached result
- whether to follow the planner’s suggestion or override it based on policy or budget
Routing must be version aware. For example, Planner v3 might emit a new schema that Executor v2 does not understand. Blindly routing based on agent name will create subtle failures. The router must match capabilities, schemas, and versions.
Routing should also be cost aware. It can choose a cheaper model for low risk tasks, route to a more expensive model only when accuracy is critical, or cap the length and depth of reasoning under high budget pressure. Rather than letting planners generate arbitrarily deep reasoning trees, the orchestrator can select the appropriate model tier or execution strategy to keep the entire workflow within budget.
In a mature system, routing decisions are governed by policies, past performance data, and cost models, not just static configuration.
Primitive 2: Distributed Scheduling (Fairness, Preemption, Deadlines)
Agents generate work in addition to executing it. A planner might produce ten subtasks, each of which spawns a retriever call, followed by summarization, validation, and execution. Without a scheduler, these tasks enter queues in whatever order they are produced. This leads to unpredictable latency, unfair resource sharing, and brittle behavior under load.
A distributed scheduler brings structure to this flow. It needs to:
- assign priorities so critical workflows are processed before background jobs
- respect deadlines, especially for real time user interactions
- enforce fairness across tenants and agent types
- allow preemption, where low priority work is delayed or cancelled when the system is under pressure
- work together with quotas and throttles from Part 12
A standard pattern is to combine static priority (critical, normal, background) with dynamic aging based on timestamps. This prevents starvation while still giving urgent work precedence during spikes.
Agents should not control their own concurrency. They should submit work and declare intent, and the orchestrator should decide when and where that work runs.
Primitive 3: Multi Agent Workflow Coordination (DAGs, State, Dependencies)
Multi agent reasoning almost always results in workflows that look like graphs. A planner creates a plan, a researcher gathers evidence, a retriever fetches documents, a summarizer condenses information, a validator checks safety or constraints, and an executor performs final actions.
The resulting structure is a directed acyclic graph (DAG) of tasks, sometimes with conditional branches and retries. The orchestrator must:
- construct DAGs from structured plans produced by planner agents
- track dependencies between nodes in that DAG
- coordinate retries or fallbacks when a node fails
- ensure schema compatibility between agents at each edge
- apply policy checks at each step, not only at the start and end
- prevent negotiation loops where two agents keep delegating work back and forth
Without coordinated workflow management, the system degenerates into ad hoc chains of calls where failure is difficult to localize, and partial success is hard to evaluate.
Workflow coordination diagram
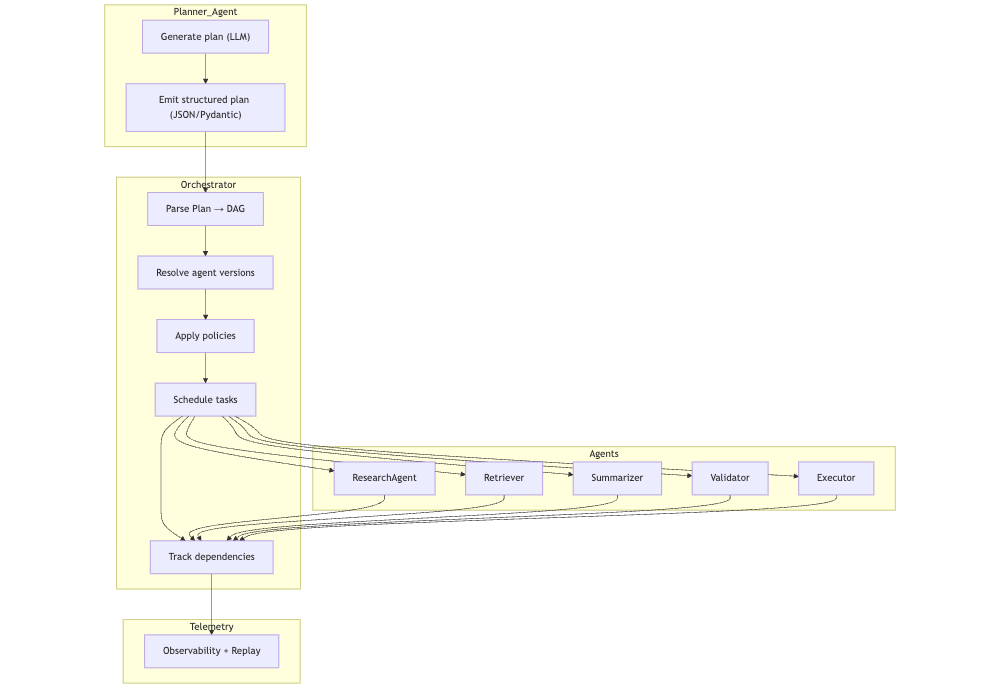
In practice, this DAG representation is also the basis for replay, auditing, and provenance in later parts of the series.
Primitive 4: Health, Failover, and Resilience
Agents can degrade or fail for many reasons. An LLM backend might return errors or slow responses. A tool API might hit rate limits or change its contract. A new agent version may have a subtle bug in its reasoning strategy that only appears under real traffic.
Without health monitoring and failover, these problems become user visible outages or silent correctness failures.
The orchestrator should:
- track success and error rates per agent version and per tool
- detect unhealthy versions and drain traffic from them
- roll back problematic deployments automatically using lifecycle data from Part 11
- route around unhealthy regions or backends
- fall back to cheaper or smaller models when premium backends are unavailable
- guard critical workflows by having safe default paths or cached results
This is standard practice in microservices, but in agent systems failures can manifest as strange reasoning, incomplete workflows, or unbounded retries. Health and failover logic needs to consider both infrastructure metrics and semantic behavior.
Primitive 5: Global Backpressure and Budget Enforcement
Part 12 introduced quotas and resource governance at the agent level. Part 13 extends these ideas to the level of the entire cluster.
Global backpressure and budgeting ensure that no single agent, tenant, or workflow can consume an unfair share of capacity or cost. The orchestrator should:
- track overall load, not just per agent usage
- propagate backpressure upstream so that agents reduce task generation when the system is near saturation
- enforce global concurrency caps that prevent overload of shared tools or model backends
- implement cost aware scheduling, where the system selects cheaper options or shortens plans when budgets are tight
- degrade gracefully under pressure, for example by dropping background jobs while preserving critical workflows
Without this, a spike from one high volume planner or a single rogue workflow can saturate resources and cause system wide outages.
Control plane feedback loop diagram
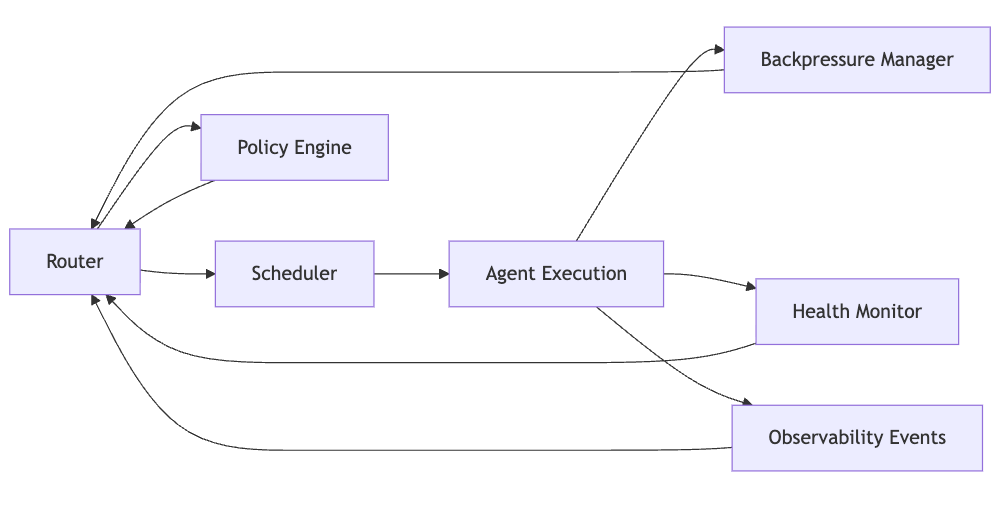
In a mature implementation, this loop is also where you plug in cost models, risk scoring, and policy overrides.
Primitive 6: Observability Hooks (Preview of Part 15)
Observability deserves its own full treatment in Part 15, but the orchestrator is where the relevant signals are generated.
Because it sits at the center, the orchestrator can emit:
- workflow DAGs that show how a task was decomposed
- agent to agent call chains
- tool call graphs linked to specific workflows
- divergence metrics between agent versions
- latency distributions and error patterns per agent, per tool, and per tenant
- backpressure and throttling events
- schema mismatches and policy denials
This telemetry is essential for debugging, drift detection, compliance, and performance tuning. It is also the input to deterministic replay and formal verification. If you cannot see what the orchestrator is doing, you cannot reason about the safety or correctness of the agent ecosystem.
Part 15 will build on this and define agent native observability and rich multi agent provenance as first class concepts.
Primitive 7: Policy and Governance Integration
Every orchestration decision is also a governance decision.
The orchestrator needs to know:
- which agents are allowed to call which tools
- which data can flow between which security domains
- which models are eligible for which risk tiers or tenants
- which workflows require human approval (preview for Part 16)
- which actions must be logged and signed
- which paths are allowed across trust boundaries
This means the control plane must invoke the same Policy as Code engine introduced in Part 4. Agents can propose actions and plans, but the orchestrator decides whether those actions are allowed, given current policy, load, and risk.
Policy at the orchestration layer is also where you encode cross cutting invariants: for example, that PII may never leave a regulated region, that certain tools are only callable by attested agents, or that specific classes of actions require a human in the loop.
In practice, distributed agent orchestration is where identity (Part 3), secure protocols (Part 10), resource governance (Part 12), observability (Part 15), and human oversight (Part 16) all meet. It is the coordination point that makes the rest of the primitives effective.
Example: Minimal Orchestrator Prototype in Python
The following Python example shows a simplified orchestration layer that is:
- version aware and cost aware in its routing
- priority based in its scheduling
- conscious of global backpressure
- capable of marking agent versions as unhealthy and avoiding them
This is not production ready code, but it captures the shape of a practical control plane that sits between workflows, agents, and tools.
import time
import random
import heapq
from dataclasses import dataclass, field
from typing import Dict, Callable, List, Optional
@dataclass(order=True)
class ScheduledTask:
sort_index: tuple = field(init=False, repr=False)
priority: int
timestamp: float
workflow_id: str
agent: str
payload: dict
def __post_init__(self):
# Combine priority and timestamp so lower priority value wins,
# and older tasks are served first within the same priority.
self.sort_index = (self.priority, self.timestamp)
class PriorityScheduler:
"""Priority scheduler with basic aging via timestamp ordering."""
def __init__(self):
self.heap: List[ScheduledTask] = []
def submit(self, task: ScheduledTask):
heapq.heappush(self.heap, task)
def pop(self) -> Optional[ScheduledTask]:
if not self.heap:
return None
return heapq.heappop(self.heap)
class Backpressure:
"""Simple global backpressure controller."""
def __init__(self, max_load: int):
self.max_load = max_load
self.current_load = 0
def allow(self) -> bool:
return self.current_load < self.max_load
def acquire(self):
if not self.allow():
raise RuntimeError("Backpressure: system overloaded")
self.current_load += 1
def release(self):
self.current_load = max(0, self.current_load - 1)
class HealthMonitor:
"""Tracks which agent versions are considered unhealthy."""
def __init__(self):
self.unhealthy: set[str] = set()
def mark_unhealthy(self, agent: str):
print(f"[health] marking {agent} as unhealthy")
self.unhealthy.add(agent)
def is_healthy(self, agent: str) -> bool:
return agent not in self.unhealthy
class Router:
"""
Version aware and cost aware routing.
For a given logical agent, choose a concrete version based on either
latest version or lowest cost.
"""
def __init__(self, agent_versions: Dict[str, list]):
self.agent_versions = agent_versions
def pick_agent(self, agent_name: str, cost_sensitive: bool = False) -> str:
versions = self.agent_versions[agent_name]
if cost_sensitive:
# Choose the cheapest version
return min(versions, key=lambda v: v["cost"])["id"]
# Otherwise choose the highest version
return max(versions, key=lambda v: v["version"])["id"]
class Orchestrator:
"""
Minimal orchestrator combining routing, scheduling, backpressure,
health monitoring, and agent handler dispatch.
"""
def __init__(self):
# Example agent registry with fake cost and version data
self.router = Router({
"planner": [
{"id": "planner-v1", "version": 1, "cost": 1.0},
{"id": "planner-v2", "version": 2, "cost": 1.2},
],
"retriever": [
{"id": "retriever-v1", "version": 1, "cost": 0.4},
{"id": "retriever-v2", "version": 2, "cost": 0.3},
],
})
self.scheduler = PriorityScheduler()
self.backpressure = Backpressure(max_load=10)
self.health = HealthMonitor()
# Map from agent version id to a handler function
self.handlers: Dict[str, Callable[[dict], str]] = {}
def register_agent(self, agent_version_id: str, handler: Callable[[dict], str]):
"""Register a callable handler for a specific agent version."""
self.handlers[agent_version_id] = handler
def submit_workflow(self, workflow_id: str, plan: List[dict]):
"""
Accept a simple plan representation: a list of steps,
where each step specifies the logical agent and payload.
In a real system this would be a DAG with dependencies.
"""
now = time.time()
for step in plan:
priority = step.get("priority", 1)
agent = step["agent"]
payload = step.get("payload", {})
version = self.router.pick_agent(
agent,
cost_sensitive=step.get("cost_sensitive", False),
)
task = ScheduledTask(
priority=priority,
timestamp=now,
workflow_id=workflow_id,
agent=version,
payload=payload,
)
self.scheduler.submit(task)
def execute_next(self):
"""Execute the next scheduled task if possible."""
task = self.scheduler.pop()
if not task:
return None
# Global backpressure gate
self.backpressure.acquire()
try:
if not self.health.is_healthy(task.agent):
print(f"[orchestrator] skipping unhealthy agent {task.agent}")
return None
handler = self.handlers.get(task.agent)
if not handler:
print(f"[orchestrator] missing handler for {task.agent}")
return None
result = handler(task.payload)
print(f"[orchestrator] {task.agent} completed task: {result}")
return result
except Exception as e:
print(f"[orchestrator] ERROR during execution: {e}")
# Mark the version as unhealthy to trigger failover next time
self.health.mark_unhealthy(task.agent)
finally:
self.backpressure.release()
# Example agent handlers
def planner_handler(payload: dict) -> str:
# Simulate planning latency
time.sleep(0.05)
goal = payload.get("goal", "unknown")
return f"plan_ok(goal={goal})"
def retriever_handler(payload: dict) -> str:
# Simulate retrieval latency
time.sleep(0.01)
query = payload.get("query", "none")
return f"retrieved(query={query})"
if __name__ == "__main__":
orch = Orchestrator()
orch.register_agent("planner-v2", planner_handler)
orch.register_agent("retriever-v2", retriever_handler)
workflow = [
{
"agent": "planner",
"payload": {"goal": "summarize report"},
"priority": 0,
},
{
"agent": "retriever",
"payload": {"query": "report data"},
"priority": 1,
},
]
orch.submit_workflow("wf-123", workflow)
while True:
result = orch.execute_next()
if result is None:
break
Why This Matters
Without a control plane, agent ecosystems eventually become unmanageable. Each agent makes local decisions about planning, tool usage, and task generation, but no component has global visibility into cost, health, version compatibility, or workflow structure. Failures propagate silently. Costs drift upward. Changes break workflows in nonobvious ways.
Distributed agent orchestration brings the same discipline that service meshes and schedulers brought to microservices, adapted to stateful, probabilistic, task-generating systems. It turns multi agent reasoning into a coordinated, observable, policy driven process rather than a collection of interacting scripts.
With a strong control plane in place, the rest of the primitives from the series become more effective and easier to apply.
Practical Next Steps
To adopt distributed agent orchestration in your own environment:
- Introduce version aware and cost aware routing for agents and models
- Add a distributed scheduler that respects priorities and deadlines
- Represent complex agent behavior as workflows or DAGs
- Implement health checks and automated failover per agent version and per tool
- Enforce global budgets and backpressure in the control plane
- Emit rich observability signals from the orchestrator, not just from agents
- Integrate policy checks into routing and scheduling decisions
Part 14 will explore secure memory governance, which becomes critical once agents start relying on long term state and shared memory structures across workflows and tenants.


