


The Missing Primitives for Trustworthy AI Agents
This installment continues our exploration of the primitives required to make safe, predictable, production-grade AI agent ecosystems:
- Part 0 - Introduction
- Part 1 - End-to-End Encryption
- Part 2 - Prompt Injection Protection
- Part 3 - Agent Identity and Attestation
- Part 4 - Policy-as-Code Enforcement
- Part 5 - Verifiable Audit Logs
- Part 6 - Kill Switches and Circuit Breakers
- Part 7 - Adversarial Robustness
- Part 8 - Deterministic Replay
- Part 9 - Formal Verification of Constraints
- Part 10 - Secure Multi-Agent Protocols
- Part 11 - Agent Lifecycle Management
- Part 12 - Resource Governance
- Part 13 - Distributed Agent Orchestration
- Part 14 - Secure Memory Governance
- Part 15 - Agent-Native Observability
- Part 16 - Human-in-the-Loop Governance
- Part 17 - Conclusion (Operational Risk Modeling)
Resource Governance (Part 12)
Today’s agent systems can generate work, not just execute it. A planner may create subtasks recursively. An evaluator may re-run comparisons when unsure. A retriever may refine queries in a loop. In multi-agent environments, these behaviors are amplified because agents call each other, delegate tasks, or retry when results look ambiguous.
This means the source of overload is often the reasoning process itself, not the result of external traffic. This is fundamentally different from traditional microservices, where overload comes from exogenous load (users, scheduled jobs, or other services). In agent systems, overload is endogenous - created organically by the LLM’s own generative behavior.
That is why resource governance is not just an efficiency concern. It is a safety primitive. Without strict quotas, throttles, priorities, and loop detection, agent clusters will eventually spiral into:
- runaway task explosions
- infinite planning loops
- uncontrolled tool invocations
- exponential cost escalation
- starvation of critical workflows
- cross-agent overload cascades
This part defines the primitives required to constrain agents so they operate within predictable, enforceable bounds.
Architecture Summary: Resource Governance Control Plane
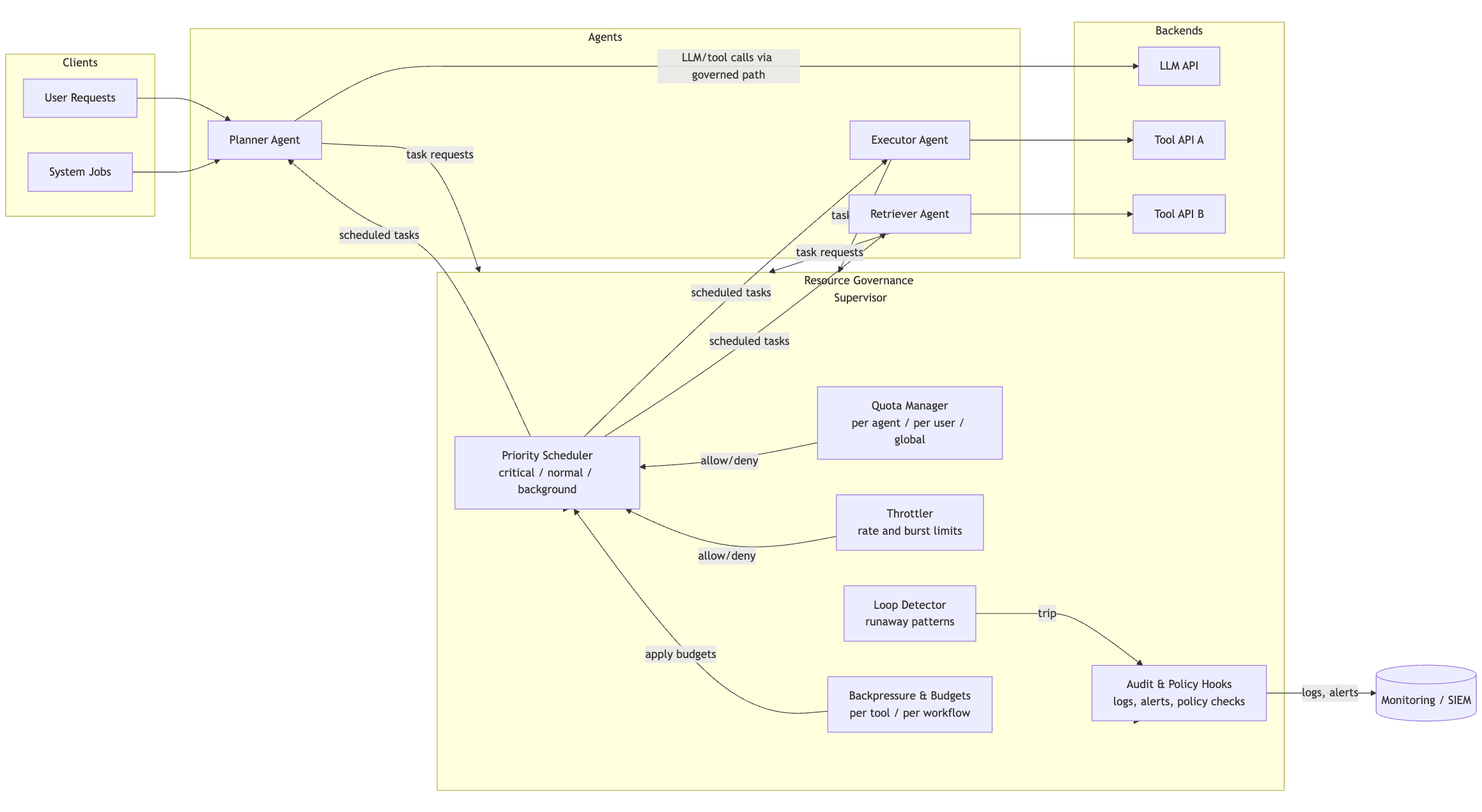
Primitive 1: Quota Enforcement
In agent systems, quotas are the first and most foundational guardrail. They define limits on how much work an agent may perform. But unlike microservices - where rate limits protect an API - agent quotas must protect the system from itself.
The fundamental risk is that agents generate secondary and tertiary work. A single iteration error can trigger a runaway chain of subtasks. Quota enforcement stops this before it becomes a systemic failure. It places hard caps on:
- the number of subtasks an agent may create
- the number of LLM tokens it may consume
- the number of tool calls it can initiate
- the total resource budget of an entire workflow
A crucial nuance is that quota enforcement must be transactional. Token consumption must be recorded before the LLM call is executed, not after, to prevent budget overdrafts if the agent crashes mid-call or if the call returns unexpectedly large outputs. In distributed systems, quotas function as pre-commit guards that prevent runaway resource consumption from beginning in the first place.
Example: Token + Task Quota Enforcement
class QuotaExceeded(Exception):
pass
class QuotaManager:
def __init__(self, token_limit: int, task_limit: int):
self.token_limit = token_limit
self.task_limit = task_limit
self.tokens_used = 0
self.tasks_created = 0
def consume_tokens(self, n: int):
if self.tokens_used + n > self.token_limit:
raise QuotaExceeded("Token quota exceeded")
self.tokens_used += n
def create_task(self):
if self.tasks_created + 1 > self.task_limit:
raise QuotaExceeded("Task creation quota exceeded")
self.tasks_created += 1
This is the conceptual skeleton. Production systems enforce quota on multiple dimensions simultaneously.
Primitive 2: Task Throttling
Even when quotas are not exceeded, agents can generate work too quickly. A planner that emits fifty subtasks per second may overwhelm tools or downstream agents even if it stays within its quota. Throttling enforces temporal fairness - slowing down work so that systems remain stable.
Failing to implement throttling leads to “event avalanches” where a burst of agent output overwhelms:
- tool API backends
- vector search infrastructure
- messaging queues
- other agents assigned to process these tasks
A throttled agent behaves more like a well-behaved distributed service, emitting work at a controlled rate rather than a single high-velocity surge.
Example: Leaky Bucket Throttler
import time
class Throttler:
def __init__(self, rate: float, burst: int):
self.rate = rate
self.burst = burst
self.tokens = burst
self.last = time.time()
def allow(self) -> bool:
now = time.time()
delta = now - self.last
self.tokens = min(self.burst, self.tokens + delta * self.rate)
self.last = now
if self.tokens >= 1:
self.tokens -= 1
return True
return False
The leaky bucket pattern is popular because it is simple, predictable under load, and easy to reason about in multi-agent pipelines.
Primitive 3: Priority Scheduling
Agents often generate many tasks of varying importance: some are user-visible (e.g., “generate final summary”), some are internal planning steps, and some belong to background workflows like nightly maintenance.
Without prioritization, “chatty” agents can starve critical work. Worse, under load, vital safety checks may become delayed behind lower-priority tasks - leading to cascading failures.
A priority scheduler ensures the system respects task importance. Combined with aging (timestamp-based ordering), it prevents starvation: low-priority tasks eventually rise in relative importance and get processed once high-priority traffic subsides.
This combination of static priority and dynamic timestamp is the standard pattern for fair scheduling across distributed systems. It ensures responsiveness during overload and fairness during stability.
Example: Priority Queue
import heapq
import time
class Task:
def __init__(self, priority: int, data: dict):
self.priority = priority
self.timestamp = time.time()
self.data = data
def __lt__(self, other):
return (self.priority, self.timestamp) < (other.priority, other.timestamp)
class PriorityScheduler:
def __init__(self):
self.queue = []
def submit(self, task: Task):
heapq.heappush(self.queue, task)
def pop(self) -> Task:
return heapq.heappop(self.queue)
This is enough to prevent user-visible workflows from being drowned by internal agent chatter.
Primitive 4: Runaway-Loop Detection
Runaway loops are one of the most common agent failure modes. Because LLM reasoning is probabilistic, small perturbations in the input or prompt can cause the agent to “interpret” instructions differently on each iteration - sometimes producing cycles like:
Planner → Executor → Planner → Executor → …
Or:
Retriever → Reranker → Retriever → …
In real systems, you must detect these loops early. Naive loop detection can rely on repeated textual signatures, but production systems require richer semantics:
- similarity of agent goals
- repeated tool sequences
- repeated patterns of subtasks
- cycles in the multi-agent call graph
- repeated failure/retry loops with little progress
The naive example below illustrates the concept but should not be mistaken for a production-grade detector.
Example: Simple Loop Signature Matcher
from collections import deque
class LoopDetector:
def __init__(self, window=20):
self.window = window
self.history = deque(maxlen=window)
def record(self, signature: str) -> bool:
self.history.append(signature)
repeats = sum(1 for x in self.history if x == signature)
return repeats > self.window // 2
In real production environments, you would track semantic similarity across signatures and build graph-based detectors over agent invocation pathways.
Primitive 5: Multi-Agent Budgeting
In multi-agent environments, one agent’s behavior can overload another indirectly. A planner generating too many tasks may cause the executor to overload a retriever. The retriever may then overwhelm the vector search subsystem, impacting unrelated workloads entirely.
This is why budgeting is global, not local. You need:
- per-agent budgets
- per-tool budgets
- per-workflow budgets
- per-tenant budgets
- global system-wide budgets
Failing to implement per-tool budgets is particularly dangerous. A high-volume agent may spike the vector search backend and thereby deny unrelated agents access to the same resource. In effect, one noisy agent becomes a denial-of-service attack against the entire ecosystem.
Budgets enforce fairness and shape how the ecosystem behaves under load, ensuring no agent (or tenant) becomes disproportionately expensive or disruptive.
Primitive 6: Cross-Agent Backpressure
Backpressure is how distributed systems protect themselves against overload. Without it, upstream agents will continue to emit tasks even when downstream components are collapsing.
In agent ecosystems, backpressure must be communicated via the secure multi-agent protocol (Part 10). This means:
- backpressure signals must be authenticated
- they must contain schema-valid metadata
- they must propagate upstream according to workflow graphs
- they can carry instructions like “retry in 500 ms” or “reduce batch size”
Without backpressure, the system has no stable equilibrium. Agents will continue generating tasks even as downstream agents reject or drop them, creating oscillatory failures.
Backpressure turns multi-agent chains from “fire and forget” into coordinated distributed workflows.
Primitive 7: Governance Integration
Resource Governance is where many of the previous primitives converge. It anchors the relationship between detection, enforcement, auditing, replay, and formal correctness.
First, resource governance ties directly into Kill Switches and Circuit Breakers (Part 6). When a quota violation occurs, the quota manager is the detection mechanism - identifying that a budget has been exceeded. The kill switch (or breaker) is the enforcement mechanism - terminating or isolating the offending agent before it harms the system. This pairing ensures that runaway behavior can be stopped deterministically rather than spiraling into a full outage.
Second, resource limits are among the easiest primitives to express in Formal Verification (Part 9). Quotas convert naturally into SMT constraints like:
total_tokens <= token_limit
subtasks <= max_subtasks
global_cost <= system_budget
This makes resource governance the most accessible entry point into integrating formal verification with agent operations. Combined with deterministic replay (Part 8), engineers can reproduce and analyze the exact sequence of events leading to a quota violation - and use solver-derived counterexamples to strengthen policies and invariants.
Resource governance is the operational backbone that ensures agent clusters do not collapse under their own weight. It is the convergence point where policy, identity, replay, and formal correctness become enforceable at runtime.
Sample Governance Configuration (YAML)
# resource-governance.yaml
global:
max_concurrent_tasks: 5000
max_tokens_per_minute: 2_000_000
max_tool_calls_per_minute: 50_000
agents:
planner:
version: "2.1.0"
quotas:
max_subtasks_per_task: 25
max_tokens_per_task: 50_000
max_tokens_per_minute: 200_000
max_tool_calls_per_minute: 5_000
throttle:
rate_per_sec: 50
burst: 100
priority:
default_class: "high"
loop_detection:
max_depth: 5
signature_window: 32
executor:
version: "1.4.3"
quotas:
max_tokens_per_task: 30_000
max_tool_calls_per_task: 100
max_tool_calls_per_minute: 10_000
throttle:
rate_per_sec: 100
burst: 200
priority:
default_class: "normal"
tools:
"vector-search":
max_qps: 2000
max_concurrent_requests: 500
priority_class: "high"
Unified Resource Governance Supervisor (Python)
Below is the full unified Python example, combining:
- quotas
- throttling
- prioritization
- loop detection
- task scheduling
- multi-agent resource windows
This illustrates how the primitives work together under a single supervisory control plane.
import time
import heapq
from collections import deque, defaultdict
from dataclasses import dataclass, field
from typing import Any, Dict, Optional, Tuple
class QuotaExceeded(Exception):
pass
class ThrottleExceeded(Exception):
pass
class LoopDetected(Exception):
pass
@dataclass
class QuotaConfig:
max_tokens_per_task: int
max_subtasks_per_task: int
max_tokens_per_minute: int
max_tool_calls_per_minute: int
@dataclass
class AgentUsageWindow:
tokens_used: int = 0
tool_calls: int = 0
window_start: float = field(default_factory=time.time)
class QuotaManager:
def __init__(self, config: Dict[str, QuotaConfig]):
self.config = config
self.agent_usage: Dict[str, AgentUsageWindow] = defaultdict(AgentUsageWindow)
def _refresh(self, agent_id: str):
usage = self.agent_usage[agent_id]
now = time.time()
if now - usage.window_start >= 60:
usage.tokens_used = 0
usage.tool_calls = 0
usage.window_start = now
def consume_tokens(self, agent_id: str, tokens: int, task_state):
cfg = self.config[agent_id]
if task_state["tokens"] + tokens > cfg.max_tokens_per_task:
raise QuotaExceeded("Task token quota exceeded")
self._refresh(agent_id)
usage = self.agent_usage[agent_id]
if usage.tokens_used + tokens > cfg.max_tokens_per_minute:
raise QuotaExceeded("Per-minute token quota exceeded")
task_state["tokens"] += tokens
usage.tokens_used += tokens
def register_tool_call(self, agent_id: str, task_state):
cfg = self.config[agent_id]
if task_state["tool_calls"] + 1 > cfg.max_tool_calls_per_minute:
raise QuotaExceeded("Task tool-call quota exceeded")
self._refresh(agent_id)
usage = self.agent_usage[agent_id]
if usage.tool_calls + 1 > cfg.max_tool_calls_per_minute:
raise QuotaExceeded("Per-minute tool-call quota exceeded")
task_state["tool_calls"] += 1
usage.tool_calls += 1
class Throttler:
def __init__(self, rate: float, burst: int):
self.rate = rate
self.burst = burst
self.tokens = float(burst)
self.last = time.time()
def allow(self) -> bool:
now = time.time()
delta = now - self.last
self.tokens = min(self.burst, self.tokens + delta * self.rate)
self.last = now
if self.tokens >= 1:
self.tokens -= 1
return True
return False
@dataclass(order=True)
class ScheduledTask:
sort_index: Tuple[int, float] = field(init=False, repr=False)
priority: int
timestamp: float
agent_id: str
task_id: str
payload: Dict[str, Any] = field(compare=False)
def __post_init__(self):
self.sort_index = (self.priority, self.timestamp)
class PriorityScheduler:
def __init__(self):
self.heap: list[ScheduledTask] = []
def submit(self, task: ScheduledTask):
heapq.heappush(self.heap, task)
def pop(self) -> Optional[ScheduledTask]:
if not self.heap:
return None
return heapq.heappop(self.heap)
class LoopDetector:
def __init__(self, window: int, max_ratio: float):
self.window = window
self.max_ratio = max_ratio
self.history: deque[str] = deque(maxlen=window)
def record(self, signature: str) -> bool:
self.history.append(signature)
repetitions = sum(1 for x in self.history if x == signature)
return repetitions / len(self.history) > self.max_ratio
Why This Matters
Without resource governance, agent systems eventually degrade into unpredictable, self-amplifying workloads. Quotas prevent runaway resource consumption. Throttles smooth event velocity. Priority scheduling ensures fairness. Loop detection guards against recursive reasoning failures. Budgets stop cross-agent overload. Backpressure provides coordinated slowdown. And governance ties it all together with policy enforcement, kill switches, deterministic replay, and formal verification.
Resource Governance is therefore not a performance optimization - it is a safety primitive and a system-wide stabilizer for complex multi-agent ecosystems.
Practical Next Steps
- Define per-task, per-agent, per-tool, and per-tenant quotas
- Add throttling using token or leaky buckets
- Introduce priority scheduling with aging
- Implement loop detection using semantic signatures
- Enforce global budgets and cross-agent backpressure
- Integrate governance signals with secure protocols
- Add audit + replay instrumentation around all budget checks
- Encode resource invariants in Z3 or TLA+


